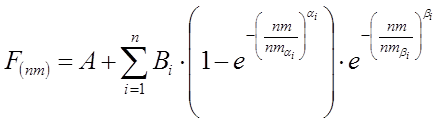Für den interessierten Leser: Einführung und Überblick der verwendeten statistischen Verfahren
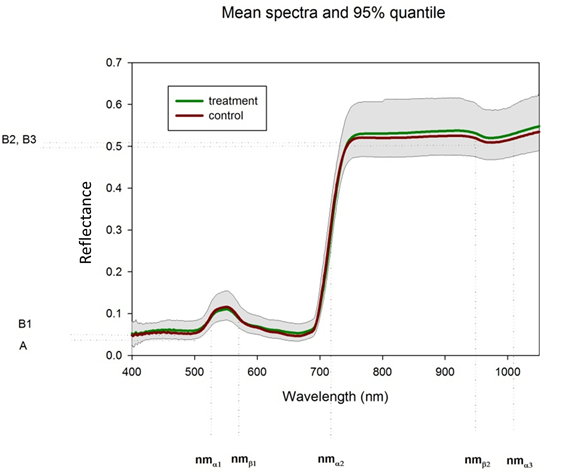
Abb. 1: Parameterbezeichnungen und Wellenlängenbereiche der Modellparameter
Nemaplot nutzt die Hyperspektraltechnologie als Grundlage zur schnellen und frühzeitigen Versuchsauswertung und
Merkmalserkennung von biologischen Gegenständen mit zerstörungsfreien Methoden. Dazu wurden verschiedene, z.T.
patentierte Auswerteverfahren entwickelt, die in den Daten auch kleine Unterschiede erkennen und statistisch absichern.
So einfach die Messungen mit hyperspektralen Sensoren durchgeführt werden können, so aufwendig erscheint die Auswertung der Informationen. Nemaplot
hat dazu spezifische Algorithmen entwickelt, welche Unterschiede in den
Spektren durch Modellanpassung, Parameterschätzungen und multivariater
Statistik ermitteln. Mit unserem patentierten Verfahren werden diese
Spektren in numerische Parameter umgewandelt und auf eine künstliche
Skalenebene abstrahiert. Das gemessene Individuum (Pflanze, Blatt, Fleisch-
oder Gewebeprobe, etc.) ist charakterisiert durch das spezifische Spektrum
oder in diesem Fall durch die spezifische Frequenz seiner Modellparameter.
Die Trennschärfe dieses Verfahrens ist hoch, so dass, gerade unter der
Verwendung der Gesamtinformation eines Spektrums, auch sehr ähnliche
Spektren vergleichbar sind. Die Merkmalsunterscheidung erfolgt in einem 2.
Schritt auf der Basis multivariater Verfahren. Wir verwenden bewusst so klassische Verfahren wie
Diskriminanz- oder Clusteranalyse. Die Güte der Verfahren ist mehr als ausreichend,
klassisch standardisiert, und
nur eventuell geringfügig schlechter als Partial Least Square (PLS) oder
Support Vector Machine (SVM) Verfahren, aber ohne deren zahlreichen,
schwach
begründeten Stellschrauben. Man erhält eine Reihe
statistischer Parameter, die wiederum qualitative, auf der Basis der
statistischen Skalenebenen z.T. aber auch quantitative Unterscheidungen
ermöglichen. Der Vergleich einzelner Parameter der Schätzer wird zur
statistischen Analyse von Behandlungseffekten angewandt. Der
Parametervergleich erlaubt die statistisch signifikante Abgrenzung und ermöglicht eine
Vergleichbarkeit von Signaturen über die Signifikanz der statistischen Tests.
Das Analyseverfahren ist auf alle spektrale Reflexionssignaturen anwendbar und nicht reduziert auf die Analyse von Vegetationskurven. Es wird die Gesamtheit der
spektralen Information für die Analyse verwendet.
Auf die mehrheitlich angewandten Indices wird verzichtet. Zur Versuchsauswertung wird eine dimensionslose Skalenebene auf der Basis von Diskriminanzfunktionen
verwendet. Diese alternative Skaleneben ermöglicht eine Bewertung
hinsichtlich der relativen Unterschiede der Versuchsglieder. Wir liefern
eine Reihe von statistischen Kenngrößen, die eine Beurteilung der Messwerte ermöglichen.
Dabei geht es nicht um die offensichtlichen Unterschiede, die sind sowieso schon visuell erkennbar sind, sondern
um präsymptomatische, frühzeitige Unterschiede, die den Behandlungseffekt demonstrieren
und den relativen Unterschied quantifizieren.
Zu diesen statistischen Parameter gehören:
Allgemeine Maßparameter, wie den c2 Test, die die Trenngüte und Gruppenzugehörigkeit der Diskriminanzfunktionen beschreiben, sowie
dessen Wahrscheinlichkeit p
des zum Testen auf Gruppengleichheit (kleine p-Werte bedeuten ungleiche Gruppen, bedingt z.B. durch Behandlungseinflüsse).
Kanonische Korrelation, als Maß für die Güte der Diskriminanzfunktionen, es gelten die üblichen Einteilungen, 0-0.3 keine Beziehung,
0.3-0.7, schwache bis mittlere Beziehung, 0.7 - 1.0 hohe Beziehungen.
Kanonische Distanz, eine dimensionslose, nach oben offene Skala, die den
quantitativen Vergleich der Intensität des Behandlungseffekts ermöglicht. Je
größer die Distanz, desto größer ist der relative Unterschied zwischen den Gruppen, auf den Behandlungsfaktor bezogen, desto stärker ist der Behandlungseffekt.
Eine ausreichende Anzahl von Wiederholungen der Versuchsglieder ist
notwendig, ganz wichtig, es muss auch eine ausreichende Anzahl von Kontrollpflanzen bei der Versuchsplanung
berücksichtigt werden. Die Anzahl der Kontrollen sollte denen der übrigen
Versuchsglieder entsprechen. Mehrmalige Messungen an einem Objekt, z.B.
Blätter einer Pflanze, sind ebenfalls empfohlen. Auch wenn es sich de facto nur um Pseudowiederholungen handelt, werden
aber Blattunterschiede, die nicht unbedingt behandlungsbedingt sind, im Mittel ausgeglichen.